ただし、競合他社よりも安いです。
Deepseekの新しいチャットボットは、この魅力的な説明で私に紹介されました:
こんにちは、私はあなたが何でも尋ねて、あなたを驚かせるかもしれない答えを得ることができるように作成されました。
今日、Deepseekの人工知能は市場で恐るべき競合他社として浮上しており、特にNvidiaの最大の株価下落の1つに貢献しています。
 画像:Ensigame.com
画像:Ensigame.com
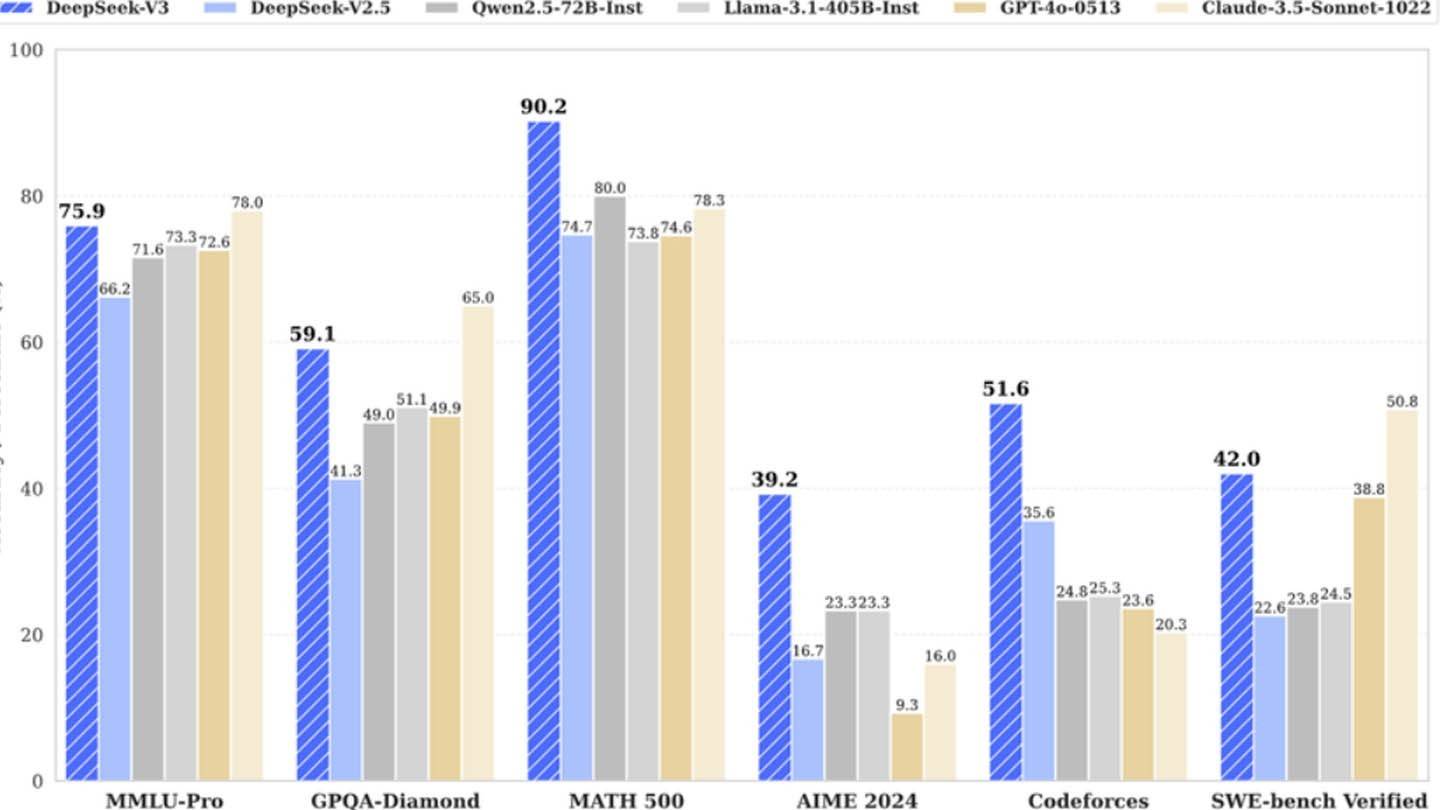
このモデルを区別するのは、革新的なアーキテクチャとトレーニング方法です。いくつかの最先端のテクノロジーを利用しています。
マルチトークン予測(MTP):このアプローチにより、モデルは文のさまざまな部分を分析し、精度と効率の両方を向上させることにより、複数の単語を一度に予測できます。
専門家の混合(MOE):Deepseekのモデルは、多様なニューラルネットワークを使用して入力データを処理します。このアーキテクチャは、AIトレーニングを高速化し、パフォーマンスを向上させます。 DeepSeek V3では、256のニューラルネットワークが使用され、トークン処理タスクごとに8つがアクティブ化されています。
マルチヘッド潜在的注意(MLA):このメカニズムは、AIが文の最も重要な部分に焦点を合わせるのに役立ちます。テキストフラグメントから重要な詳細を繰り返し抽出することにより、MLAは重要な情報が欠落するリスクを減らし、AIが入力データの重要なニュアンスをより適切にキャプチャできるようにします。
中国の主要なスタートアップDeepSeekは、わずか2048グラフィックスプロセッサを使用してDeepSeek V3のトレーニングにわずか600万ドルを費やしたと主張して、最小限のコストで非常に競争力のあるAIモデルを作成したことを誇っています。
 画像:Ensigame.com
画像:Ensigame.com
しかし、Semianalysisのアナリストは、Deepseekが約50,000のNvidia Hopper GPUで構成される実質的な計算インフラストラクチャを運営していることを明らかにしました。これには、10,000 H800ユニット、10,000高度H100、追加のH20 GPUが含まれます。これらのリソースは、複数のデータセンターに広がり、AIトレーニング、研究、財務モデリングに使用されます。
同社のサーバーへの総投資は約16億ドルで、運用費用は9億4,400万ドルと推定されています。
Deepseekは、中国のヘッジファンド高飛行者の子会社であり、2023年に別のAIに焦点を当てた部門としてスタートアップを紡ぎました。クラウドプロバイダーに依存するほとんどのスタートアップとは異なり、DeepSeekはAIモデルの最適化を完全に制御し、迅速なイノベーションを可能にします。同社は自己資金のままであり、柔軟性と意思決定速度を向上させています。
 画像:Ensigame.com
画像:Ensigame.com
さらに、Deepseekの一部の研究者は、年間130万ドル以上を稼ぎ、中国の主要な大学から最高の才能を引き付けます(同社は外国人の専門家を雇いません)。
これらの事実を考えると、わずか600万ドルで最新のモデルをトレーニングするというDeepseekの主張は非現実的であるように見えます。この図は、トレーニング前のGPU使用コストのみをカバーしており、研究費、モデルの改良、データ処理、または全体的なインフラストラクチャコストは含まれていません。
Deepseekは設立以来、AI開発に5億ドル以上を投資してきました。ただし、その無駄のない構造により、より大きな官僚的企業よりもAIイノベーションをより積極的かつ効果的に実装することができます。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekの例は、資金提供された独立したAI企業が実際に業界の巨人と競争できることを示しています。しかし、専門家は、同社の成功は数十億の投資、技術的なブレークスルー、強力なチームによって推進されている一方で、AIモデル開発の「革新的な予算」についての主張はやや誇張されていると指摘しています。
それにもかかわらず、Deepseekのコストは競合他社のコストよりも低いままです。たとえば、DeepseekはR1に500万ドルを費やしましたが、ChatGpt4oは訓練に1億ドルの費用がかかりました。